“大数据”英文名称Big data。这个概念是近几年开始火起来的,现在可谓是无处不在了。在了解什么是大数据之前,我们先了解一下什么是传统数据?

传统数据就是IT业务系统里面的数据,如客户资料、财务数据等。这些数据是结构化的,量也不是特别大,一般只是TB级。对比传统数据,还有一种叫“新数据”,是来源于社区网络、互联网等渠道,包括文本、图片、音频、视频等非结构化的数据。目前全世界75%以上都是非结构化数据,而且还一直呈现爆炸性的增长。我们看看下面的图就更好理解了:

大数据就是:结构化的传统数据+非结构化的新数据。
因而,大数据还具有以下特点,简称“4V”:
Volume(大量):数据体量巨大,从TB级别,跃升到PB级别;
Variety(多样):数据类型繁多,有网络日志、视频、图片、地理位置信息等;
Velocity(高速):处理速度快,可从各种类型的数据中快速获得高价值的信息,这一点也是和传统的数据挖掘技术有着本质的不同;
Value(价值):只要合理利用数据并对其进行正确、准确的分析,将会带来很高的价值回报。
第二步:大数据组成
大数据系统由基础设施、平台和应用组成。对比我们平时使用的电脑,基础设施就是电脑这台硬件,平台就是装在里面的操作系统,应用就是操作系统上面的各种应用程序。
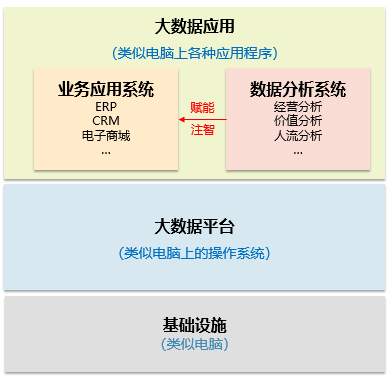
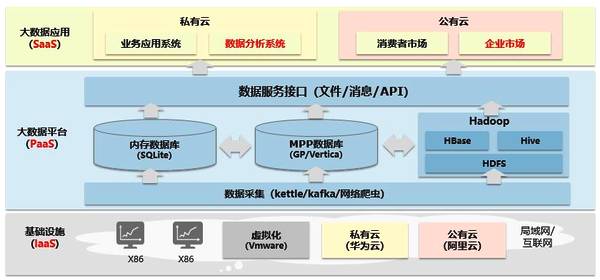
大数据的应用五花八门,但总体上可分为“业务应用”和“数据分析”两大类。
前者包括ERP、CRM等业务系统,后者指的是各种分析应用,包括经营分析、价值分析、人流分析等等。分析系统从业务系统获取源数据,经过分析后可以反哺业务系统,对其进行赋能(注智),让其具有智慧。说到这里,大家是不是觉得有点熟悉了?跟我们的BI是不是有某些联系呢?没错了,“大数据平台”和“数据分析系统”加在一起就是BI的升级版啊!既然是升级版,它与传统BI有什么区别呢?请看下面就知道啦。
* 成本更低廉
去IOE,硬件采用廉价的X86,软件更多使用开源,节省成本
* 容灾性好
平台部署在X86 集群上,机器出问题可随时切换
* 扩展性好
X86 集群可根据需要随时进行扩展,提高灵活性
* 处理效率高
当数据达到TB级别,处理效率显著提高
* 处理类型多
可以处理结构化、半结构化、非结构化数据
进一步挖掘价值
* 最新的
处理的数据量大,类型多,因而可进一步挖掘数据的价值。
是不是有很多升级的地方呢?为了支持这些升级,大数据系统需要具备哪些功能呢?这就涉及到架构问题了,继续往下看。
第三步:大数据架构
我们已经知道大数据系统由基础设施、平台和应用组成,我们现在进一步细分,请看下图:
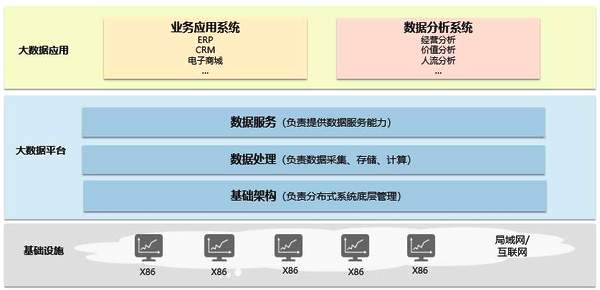
基础设施由通过局域网或互联网连接的X86 集群组成,为大数据平台提供最基本的硬件支持。
大数据平台由基础架构、数据处理和数据服务三部分组成:
基础架构负责对基础设施进行系统管理,为数据处理提供分布式底层服务;数据处理负责数据的采集、存储、计算;数据服务负责将处理后的数据提供给上层应用使用。大数据应用是面向用户的各种应用系统,包括业务应用和数据分析。大数据系统的总体架构就是这样子,是不是跟我们平时见到的BI架构很像呢? 通过这个表格对比我们就更清楚了:

下面我们将围绕这个架构展开说明。
第四步:虚拟化
基础设施提供计算、存储、网络三种能力,是大数据平台的根基。但是如何解决以下问题:
* 大量的机器如何管理
当集群的状态改变,也即增加或者减少一些机器的时候,难道要去修改平台的配置吗?
* 如何充分利用系统资源
当集群的能力只使用了一部分,而这个时候需要一部新的机器用来部署其它系统,难道是从集群上拆下一部机器来提供吗?
* 如何解决弹性问题
当高峰期的时候,系统可能需要 20 部机器,平时只需要 10 部。那么我们是提供多少部合适呢?如果提供 20 部,平时空闲下来的 10 部如何处理?
这些问题有一种解决方法:虚拟化。就是把集群作为一个整体进行管理,可以根据需要从某些机器中调配相关资源,快速组成一部“新的机器”。例如可以用机器A的CPU1/ 2 性能、1/ 3 的内存,和机器B的1/ 5 硬盘组成。
当集群的状态改变时,我们只需要修改虚拟化软件的配置,减少对平台的影响。当集群有多余的资源时,可以虚拟出一些新的机器给其它系统使用,充分利用了系统资源。
虚拟化的主流商业软件是Vmware,开源的软件有Xen、KVM等。
第五步:云化
虚拟化虽然带来资源配置的灵活性,但也有明显的缺陷。配置一部“新的机器”需要人工操作,配置非常麻烦,最多只能管理几百台电脑的规模,作为企业内部的应用是可以的。但对于提供公众服务的互联网公司来说,需要上万部电脑的规模,通过虚拟化的方式是行不通的。所以又有了新技术的出现:云化,也即把基础设施作为一项服务提供。请看下图:
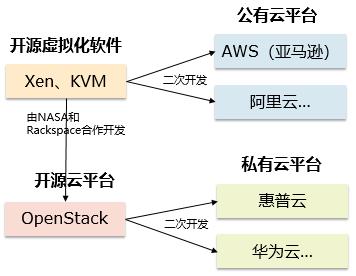
最早是亚马逊基于自身电商业务的发展,传统的IT架构已经满足不了需求,所以基于开源的虚拟化软件开发了AWS(Amazon Web Service),可以支持超大规模的集群应用。在解决自己的业务需求后,亚马逊发现可以把这项技术作为一项单独的业务推向市场,这就是现在稳居全球市场头把交椅的的亚马逊云服务。同样的背景,阿里巴巴也基于Xen推出了市场化的阿里云,现成已经成为国内云市场的老大。由此我们也知道为什么云服务做得最早、最好的都是互联网公司了吧?因为他们有自身的业务在驱动。规模上万部的机器,以资源池(数据中心)的形式分布在不同的地域上(很多建设在广西、贵州、内蒙等欠发达省份,电费、人工比较便宜,又可以促进当地就业),通过调度中心进行统一管理,这就是公有云平台。
在亚马逊开展商业化云服务的同时,美国另一家叫Rackspace的公司也推出OpenStack在跟亚马逊竞争。无奈竞争不过人家,最后决定和NASA(美国国家航空航天局)合作,把OpenStack开源,一起成立了开源云平台。后来各家传统的IT巨头纷纷加入这个开源的社区,经过二次开发和包装后推出了自己的私有云平台,和自家的硬件或解决方案打包一起销售。
不管是公有云,还是私有云,都是实现了基础设施的时间灵活性和空间灵活性,把基础设施作为一项服务提供,也即:Infranstracture as a Service(IaaS)
第六步:Hadoop
大数据平台的基础架构采用Hadoop,包括HDFS和MapReduce两部分:
* HDFS在集群上实现分布式文件系统,负责对文件的操作。(类似windows下的文件管理系统NTFS)
* MapReduce在集群上实现分布式计算和任务处理,负责将作业分解成多个任务,分派到多部机器一起执行,同时监控执行情况,保证每个任务都能顺利执行,所有任务结束后再将结果汇总。(类似多个人一起数图书馆的书,每个人算一个书架(Map),最后把所有结果加在一起(Reduce))
那么,如何把Hadoop安装到集群下面那么多机器上呢?每部机器的配置、操作系统都可能不一样。
解决办法就是采用“容器“技术:先将Hadoop打包到一个封闭的容器中,再统一发布到各部机器上。容器能够根据机器实际环境做出相应的调整,保证Hadoop的顺利安装。(类似用统一规格的集装箱来运送货物)
容器的主流技术是开源的Docker。不仅仅是Hadoop可以通过容器进行安装,所有的应用都可以使用。
现在已经在集群下每部机器安装了Hadoop,那么Hadoop是如何运行的呢?请看下图:

Hadoop把集群下其中一个节点拿来当Master,其它节点当Slave。对于HDFS来说,Master就是NameNode,负责管理文件系统的命名空间和控制客户端访问;Slave就是DataNode,负责管理存储的数据。对于MapReduce来说,Master就是JobTracker,负责调度构成一个作业的所有任务,这些任务分布在不同的TaskTracker上;Slave就是TaskTracker,负责执行由JobTracker指派的任务。
Hadoop已经衍生出很多不同的升级版本,目前应用最成熟、最广泛的是Spark。
第七步:数据处理
数据处理是对数据的采集、存储和计算。因为大数据有各种各样的应用,不同的应用,数据的种类、结构,数据的实时性要求都可能不同。所以要根据实际情况进行数据库选型,这是大数据平台设计的关键,将影响到整个平台的整体性能。不同的数据库类型可以进行混搭,同时采用不同的ETL技术。
目前常见的各种数据库类型如下:
* 传统数据库
主流数据库有Oracle、DB2、MySQL,主要应用于小规模应用系统,或者为了利用已有的资源,同时降低系统升级的风险,采用的ETL技术是Datastage、Kettle等。
* 内存数据库
主流数据库有SQLite、HANA,主要应用于对实时性要求高,需要实时处理的数据,如实时指标展示,精准营销等,采用的ETL技术是流处理技术kafka。
* MPP数据库
MPP是指大规模并行处理,MPP数据库支持X86 集群,常见的有Greanplum、Vertica等,主要应用于大规模结构化数据分析,如信令分析、DPI分析,一般采用Kettle作为ETL工具。
* NoSQL数据库
NoSQL是指半结构化或非结构化数据库,主流的数据库有MongoDB、HBase和HDFS等,HBase用来存储半结构化或结构很稀疏的数据,HDFS用来存储非结构化数据。HBase和HDFS都不支持SQL,需要使用Hive作为SQL接口执行一些简单的查询操作。NoSQL数据库基于Hadoop平台,主要应用于大规模半/非结构化离线分析,例如互联网数据分析、文档分析等,一般采用网络爬虫技术进行ETL。
第八步:数据服务
经过处理后的数据,一般不提供给上层应用直接用SQL访问,这一点与数据仓库不同。数据仓库把采集过来的数据经过处理后存储在汇总层,上层应用直接用SQL访问。但大数据平台把处理后的数据进行封装和分类,为上层应用提供可灵活调用的数据服务接口,可以保证数据访问的规范性和安全性。接口的承载方式有:文件、消息、API、SDK、界面集成,其流程如下:
* 数据格式化
对原始数据进行格式化,过滤字段并进行排序。
* 数据封装
对格式化后的数据及其元数据进行封装,以实现对外一致、标准化的数据访问接口。
* 数据分类
根据封装后的数据,按主题进行接口分类。
* 数据服务
上层应用可通过数据服务接口调用数据,实现数据的服务功能。
数据服务接口屏蔽掉大数据平台的所有细节,把平台作为一项服务提供给应用使用,这种方式称之为Platform as a service(PaaS)。
在公有云提供商中,一般都会有对应的PaaS服务提供,如阿里云的EDAS(企业级分布式应用服务)。
私有云是企业自建,对数据访问的控制没那么严格。为了开发效率,应用通常可以通过SQL直接访问数据。
第九步:大数据应用
前面已经为大家介绍了基础设施和大数据平台,也介绍了私有云和公有云的区别。对于大数据应用来说,私有云上的应用,就是我们平时说的企业信息化系统,只不过这些系统是采用大数据的架构。而公有云上的应用,指的是我们平时使用的互联网服务,如微信、微博、支付宝等。但是,随着云服务市场的发展,越来越多的传统IT厂商也通过公有云为公众提供服务,比如我们熟悉的 MicrosoftOffice 365。这种把软件作为服务提供的方式称之为:Software as a Service(SaaS)。
在国际市场,比较常见的企业级SaaS服务有客户管理服务Saleforce、团队协同服务Google Apps等等。国内市场的金蝶、微软、Oracle也都提供多种SaaS产品和服务。我们可以看一下IDC对2017- 2022 年中国公有云整体市场的预测(单位:百万美元):

从上表可以看出,整个云服务市场的年复合增长率达到了41%,其中PaaS服务增长最快,达到了55.7%。中国企业级SaaS市场份额全球第二,未来五年依旧呈现快速增长态势,年复合增长率达到35.7%。到了 2022 年,整个SaaS市场规模达到 400 亿人民币。
第十步:云计算
大家有没有发现,前面说了那么久,还没提到云计算呢?其实前面都是铺垫,现在就要给大家介绍云计算了。云计算就是一种IT架构,是一种IT资源的交付和使用模式。前面介绍的IaaS、PaaS、SaaS就是云计算架构下对不同资源的交付模式,分别将基础设施、平台、软件以服务的形式提供给用户使用。
到目前为止,相关的概念都介绍给大家了。我们把前面的大数据架构图进一步细化,大家是否看得懂了呢?